인과추론과 실무 빌더를 맡으면서, 온라인 통제 실험에 대한 주제를 발표하게 되었습니다.
평소에 관심이 있던 분야라, 공부할 기회가 있으면 좋겠다 싶었는데 스터디를 통해 좋은 기회를 얻어 발표하게 되었습니다.
아래는 프로젝트 발표에 대한 정리본입니다.
무작위 실험의 순서
(0) 가설 및 실험 디자인 – Sample Size(how long?), OEC, Guardrail Metric, Data Quality etc..
(1) 실험 할당 – 고유 식별자에 기반하여, 사용자를 그룹으로 나누고, 제품 변형(variant) 하나로 할당
(2) 실험 실행 – 사용자의 행동 데이터를 Logging
(3) 실험 로그 처리 - Log 데이터를 저장소로 업로드하여 처리 (e.g., 서버 로그와 실험 metadata 결합)
(4) 실험 분석 - variant로 영향을 받은 사용자로 필터링 처리된 로그를 분석하는 단계
(5) Ship or Abort – 실험한 Feature를 반영? or 실험 Reproduce? or Abort ?
무작위 실험의 패턴 (Engineering)
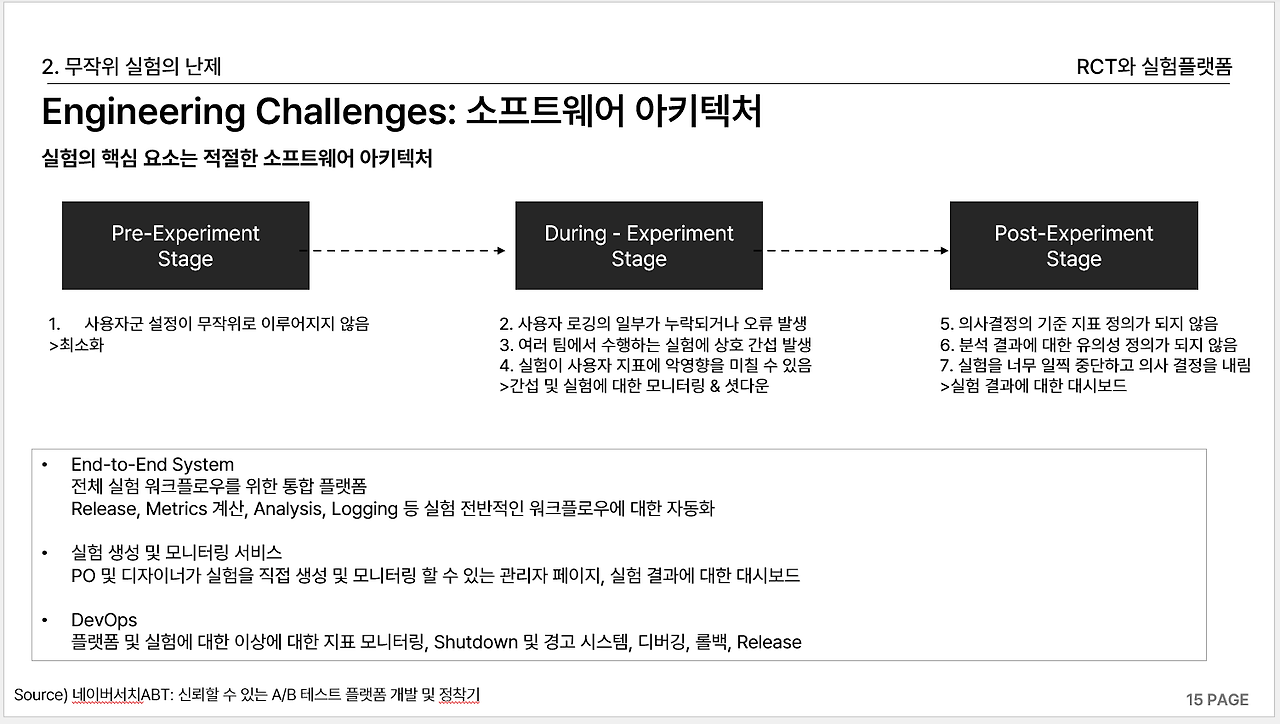
- Assignment : Hash Function
- Randomize 요청에 따라 Deterministic하게 응답 관리자가 설정한 비율대로 올바르게 배정
- Murmur Hash3, SHA1(Facebook PlanOut), SHA256, MD5
- Bucket(Slot)은 물리적으로 존재하는 저장 공간이 아니며, 논리적으로 존재하는 개념
- 동일한 사용자 그룹이 여러 테스트에서 지속적으로 변경 사항을 경험할 때 발생
- 버킷 할당에 사용되는 일관된 시드 때문에 버킷은 이전 A/B 테스트를 "기억"하여 후속 테스트 결과에 영향
- Release :
- Feature Toggles + Release Strategy (Blue & Green, Canary)
- Architecture:
- 사용자 로그 및 메타 데이터 저장
- 실험 관리와 Config 서버(실험 정보와 실험 정책 저장)
- 지표 계산 및 대시보드 결과 생성 파이프라인
무작위 실험의 패턴 (Analytics)
- Randomization Unit = Analysis Unit
->Independence of randomization units -> User Level Randomization - 실험군과 대조군의 간섭 Interference (Network Effect) -> 네트워크 클러스터 생성 [Detecting interference: An A/B test of A/B tests]
-> 클러스터에 따라 사용자를 무작위로 처리하여 동일한 클러스터의 모든 사용자가 동일한 치료 그룹에 속하도록 처리

- Selection Bias 처리 하기 위한 패턴 A/A Testing(Randomization Check) & SRM(Sample Ratio Mismatch)
-> A/A Testing : 부스트트랩된 A/A 테스트에서 P값 분포가 균일한지 테스트- H0: average metric in group A = average metric in group B
- H1: average metric in group A ≠ average metric in group B
- DoorDash 사례처럼 회귀로 처치에 영향을 주는 변수를 통제하는 방식 활용 가능
[Addressing the Challenges of Sample Ratio Mismatch in A/B Testing]
- SRM은 Microsoft에서 지난 1년 동안 수행된 실험에서 약 6%를 자치할 만큼 일반적인 Data Quality 문제
- Variance와 민감도(Conditional Triggering & CUPED)
- 트리거 분석은 트리거 조건을 충족하지 못한 사용자의 이벤트를 제외
- Low Traffic에서 작은 효과를 탐지하기 위해서 CUPED-adjustment 필수
CUPED-adjusted metric =metric - (covariate - mean(covariate)) x theta
- Conditional Triggering: A/B 테스트가 진행되는 화면에 접근하기 어려울 때, Treatment를 받지 못한 사용자를 실험에 포함 시키면 오버트래킹 현상 (ATE가 0 -> Variance 증가) 작은 변화를 감지하기 어려움
- Novelty & Primary effect-> 신기 효과 (Novelty Effect)
변화를 좋아하고 기존 제품/방식보다 새로운 기능을 선호하여 발생하는 효과- 처치 효과가 언제 안정화되는지 확인하려면 (1) 실험을 오래 실행 (2) Novelty & Primary에 영향을 받지 않는 신규 사용자를 통해 실험
- 신규 사용자는 제품을 처음 사용하기 때문에, 두 효과에 영향을 받지 않음 / 제품 사용 기간에 따라 가중치를 줄 수도 있음
- 초두 효과 (Primacy Effect)
사용자들이 기존 제품/방식에 익숙하고 변화를 꺼려하여 발생하는 효과
표본의 수 고려
- 테스트 수행 기간을 정하기 위해서는 테스트를 위한 샘플 사이즈를 알아야 하며, 요구되는 파라미터
(1) Type II 에러율 β 또는 Power (1−β) -> 업계 표준 0.8
(2) 유의 수준 α -> 업계 표준 0.05
(3) 최소 검출 가능 효과 (Minimum detectable effect, MDE) - 샘플 사이즈를 알게 되었다면 샘플 사이즈를 사용자 수로 나눠 테스트 수행 기간을 구할 수 있음
- 일반적으로 2주 정도는 테스트하길 권장하지만 데이터를 더 수집할 수 있다면 길 수록 좋음
일주일 미만인 경우에는 주간 패턴을 포착하기 위해 최소 7일 동안 실험
- 일반적으로 2주 정도는 테스트하길 권장하지만 데이터를 더 수집할 수 있다면 길 수록 좋음
- 추가적 고려 사항
- 온라인 실험의 상황에서 데이터의 왜도나 첨도가 높은 경우, 표준 정규 분포로의 근사가 완벽하지 않을 수 있음 Alex Deng은 데이터 비대칭 상황에서 엄밀한 표본크기 결정과 정규 분포 근사를 위해 n > 100*s^2를 경험적 규칙으로 제안 (s는 왜도)
- Kohavi et al. (2014)는 유사당 수익 지표가 17.9의 왜도를 가져, 30,000개의 표본 크기가 필요하다고 주장 → Capping으로 필요한 표본을 줄이기
- 베르누이 분포와 같이 0과 1로 데이터가 구성된 경우 Capping이 불가능 한데, 이때, 라플라스 스무딩으로 인위적으로 새롭게 평균을 계산하여 신뢰 구간 개선
더 많은 자료는 가짜연구소 인과추론 실무 스터디 Github을 참고해주세요.
https://github.com/CausalInferenceLab/causal-inference-practice
'블로그 > 인과추론' 카테고리의 다른 글
| [Causal Inference] Difference in Difference(DID) (0) | 2022.10.28 |
|---|---|
| [Causal Inference] Causal Models (0) | 2022.09.15 |

