2019년 10월 11일 위세아이텍에서 주최한 '인공지능 개발전략과 산업별 사례'에서의 딥러닝 기반 금형 센서 데이터 이상 탐지 발표 사례를 정리한 글입니다.
Rana, Annie lbrahim et al (2016)에 따르면 이상치 탐지 분석이 통계기반에서 기계학습기반으로 변하고 있으며, 기존 통계기법보다 향상된 성능을 보인다고 한다.

이상 탐지
이상 탐지는 시계열 데이터에서 보편적인 패턴에서 벗어나거나 벗어나려는 징후가 있는 패턴을 찾는 분석
- 뚜렷한 패턴을 보이지 않지만 이상을 일으킴
- 보편적인 것에 대비 상대적으로 수가 적음
- 지금은 문제가 없지만 앞으로 문제가 발생할 수 있는 패턴
기계학습을 이상 탐지에 적용할 때, 쉽게 생각하면 이진 분류 모델로 생각할 수 있는데 이진 분류로 판단하면 아래와 같은 문제가 발생한다.
1. 분석으로 사용할 정량적인 데이터를 얻을 수 없으며, 정확한 시점에 이상 징후를 바로 알아내기 어렵다.
2. 이상인 데이터가 정상 데이터에 비해 매우 적다
3. 이상으로 라벨링 되었다고 해도 정상에 비해 그 차이가 뚜렷하지 않다.
따라서 데이터의 Feature를 학습해서 분류하는 이진 분류로 태스크를 정의하기에 성능에서 문제가 발생한다.
이상 발생 시점에 의한 구분
초기 이상 탐지 모델이기 때문에, 미래를 예측하여 문제가 발생하는 것에 대비하는 모델을 만들기에는 어려움이 많았음.
따라서 초기에는 무엇이 이상인지 정의하고, 이를 토대로 라벨링을 보안해가면서 미래에 예측 가능한 모델을 만드는 것이 목적임
1. 라벨링 없음
2. 시계열 데이터 처리
2.1 수집 주기 불균형
2.2 하나의 설비에 다양한 제품 생성
3. 다변량 데이터 - 17개 센서
4. "과거 5분 동안의 센서의 흐름을 보고 현재 상황을 판단"
이상 탐지 분석 및 문제 해결
1. 라벨링 없음 -> 시계열을 고려한 비지도 학습으로 해결
Outlier Detection을 통해 최소한의 정상(정상 데이터 중에서 가장 보편적인 데이터)을 정의함.

해당 알고리즘 4가지가 모두 정상이라고 분류한 데이터는 "최소한의 정상" 데이터라고 함
2. 시계열을 고려한 비지도 학습을 어떻게 할 것인가?
모델은 Autoencoder에 LSTM cell을 적용해 시퀀스 학습이 가능한 LSTM AutoEncoder을 활용

2-1. 일정하지 않은 주기를 어떻게 처리할까?

어떤 데이터는 1분 후에, 어떤 데이터는 4분 후에 데이터가 수집되었음. 따라서 평균, 선형보간법, 운영 Cycle 분리로 주기를 일정하게 맞추어 주었음.

2-2. 하나의 설비에서 다양한 제품 생산

하나의 설비 데이터에서 다양한 금형을 제조한다. 따라서 같은 센서 데이터로 수집이 되어있기 때문에, 데이터를 분리하여 각각 모델을 만들어 줌.
3. 성능 측정
위에서 정의한 최소한의 정상 데이터만을 활용하여 17개의 센서 데이터를 Input 데이터로 활용하였으며, 잘 학습하면 잘 복원된다는 Auto Encoder의 특징으로 Reconsturction error를 계산함

만약 정상 데이터가 들어오게 되면, Input data를 잘 복원하여 Output data와 비슷해지기 때문에, Reconsturction error이 낮아지게 될 것이고, 정상 범주가 아닌 데이터가 Input으로 들어오게 되면 Output data와 차이가 생기기 때문에 Reconsturction error 이 높아지게 될 것임
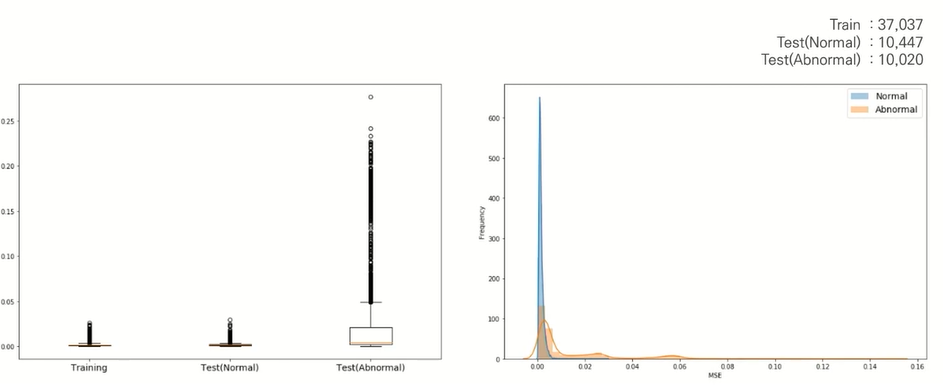
4. 그럼 얼마나 Reconsturction error 값이 높아야 비정상일까?

Precision, Recall, F1 score를 기준으로 복원 에러 값을 조정해가면서 이상과 비정상을 가장 잘 구분하는 Reconsturction error를 기준으로 선정함
정리:
개인적으로 초기 이상치 모델을 만들 때, 빠르게 활용할 수 있는 유즈 케이스라고 생각한다. 특히, 다양한 통계 기반의 이상치 탐지 모델을 활용해 최소한의 정상을 구하는 아이디어는 활용할만하다.
하지만 여전히 몇 가지 의문이 있다.
1) Reconsturction error값의 임계치를 구하는 방법에서 데이터가 비정상 / 정상 인지를 알지 못하는 상황인데 어떻게 F1 / Precision과 같은 분류 성과를 얻을 수 었었을까?
2) 하나의 설비에서 제조되는 제품이 다르다면, 제품별로 segment를 했을 때 설비 데이터의 timestamp가 각 제품 생산 일정에 따라 중간중간 discontinued time series 일 확률이 높다. 이를 어떻게 처리했을까?
참조: https://www.youtube.com/watch?v=eF4QPN58CJc
'블로그 > 딥러닝' 카테고리의 다른 글
| [RAG] RAG 성능 향상을 위한 Re-ranking (1) | 2024.07.11 |
|---|---|
| 딥러닝의 과대적합(Overfitting)을 해결하자 (0) | 2023.04.24 |
| 단층에서부터 Deep한 다층 퍼셉트론까지(Universal Approximation Theorem) (0) | 2022.08.13 |
| 역전파 알고리즘(Back Propagation)과 Delta Rule(1) (0) | 2022.07.06 |
| MLE(Maximum Likelihood Estimation), 음의 로그우도(Negative log-likelihood) (0) | 2022.06.30 |



